CUDA 11.2で導入されたcudaMallocAsyncとcudaFreeAsyncについて
これはrioyokotalab Advent Calendar 202018日目の記事です.
何の話か
CUDA 11.2からcudaMallocAsync,cudaFreeAsyncという関数がCUDAに追加されました.
これと同時にmemory poolという概念がCUDAのメモリにも導入されました.
cudaMallocAsyncはmemory poolに指定したサイズのメモリ領域がある場合はそれを確保し,ない場合は普通にメモリを取りに行きます.
cudaFreeAsyncはmemory poolへメモリを返します.
memory poolにはデフォルトのものとと我々開発者が作成できるものの2種類があります.
この記事はこのAsync関数の性能・挙動について書きます.
評価プログラム
評価にはこちらのコードを用いました.
このプログラムでは,頻繁にmalloc/freeを繰り返した場合の処理時間を調べます.
そのために単にメモリを確保し,要素ごとの演算を行うだけのカーネル関数を呼び,終わり次第freeします.
これを4回行います.
この際malloc/freeにcudaMalloc/cudaFreeを使う場合は逐次実行,cudaMallocAsync/cudaFreeAsyncは4 streamに分けて実行するようにし,それぞれの処理時間を比較します.
計算環境
- NVIDIA GeForce RTX 3080
- CUDA 11.2
- NVIDIA Driver 460.27.04
結果
| cudaMallocAsync / cudaFreeAsync | cudaMalloc / cudaFree | |
|---|---|---|
| 計算時間 | 0.2112 [秒] | 12.69 [秒] |
Asyncの方が圧倒的に速いですね.
この原因は主にcudaFreeにあるようです.
プロファイリング
Nsight Systemsで処理のタイムラインを見てみます.
普通のcudaMalloc/cudaFree
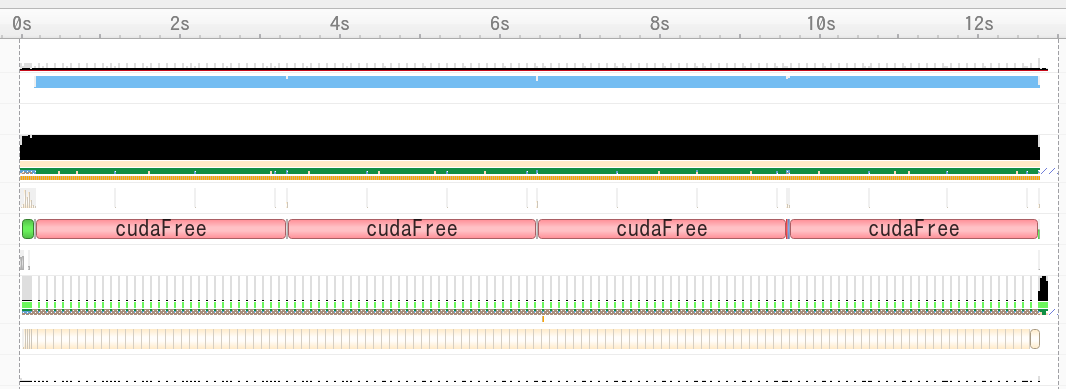
cudaFreeにほとんどの時間が使われているのが見えます.
この時のメモリの使用量の推移をお手製の gpu_logger
で見てみます.
このプログラムはNVMLを用いて,好きなプログラムを実行しながらGPUで確保されているメモリ量を記録していくことができます.

今回の評価プログラムでは1回のmallocあたり4GiBを確保します.
cudaMalloc / cudaFreeは逐次実行なため,常に4GiBちょっと取られている状態が見て取れます.
freeの最中でもNVMLからはfree開始時の容量が見えるのですね.
また,単純に考えて1回のfreeに3秒ほどかかっていることが計算できます[A].
Asyncのmalloc/free
同様にNsight Systemsでタイムラインを見てみます.
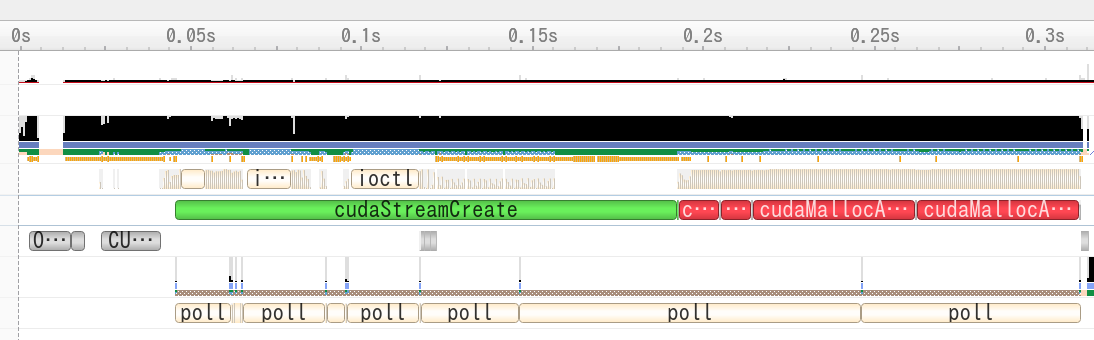
4つの赤い四角がcudaMallocAsyncとなっています.
cudaFreeAsyncはcudaMallocAsyncの隙間にあるのですが,相対的に時間が短くほとんど無視できる時間となりました.
しかし,[A]
から4GiBのfreeには3秒ほどかかるはずで,これはどこへ行ったのかが気になります.
実はプロファイル結果には続きがあります.
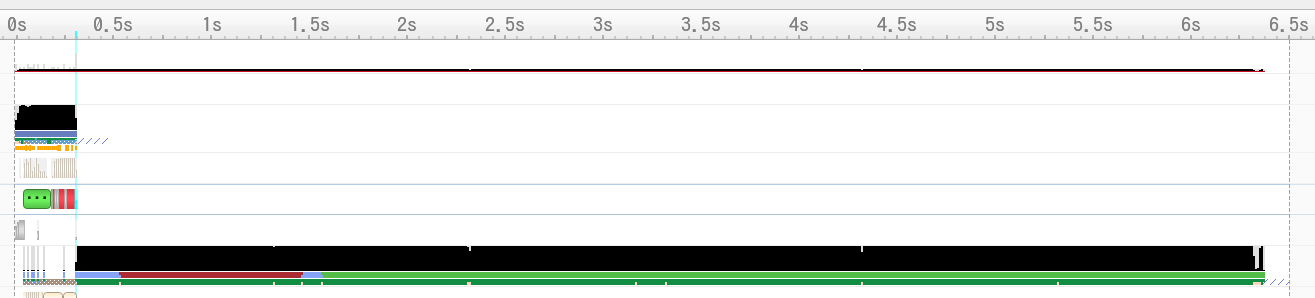
後ろに空白の処理が6秒ほどあり,およそ8GiB分くらいをfreeできる時間となっています[B].
では先ほどと同様にメモリ使用量の推移を見てみます.

このグラフを見ると,
- 複数のstreamが順にmallocを行いGPUの搭載メモリ量に達するまでmallocして行くが,いずれ確保できなくなる
- あるstreamで処理が終わるとfreeが始まる
- freeにより空き容量が増えると指定量(今回は4GiB)を確保できていなかったstreamが確保しに行く
最後0.20秒後に一気にメモリ使用量が0となっていますが,その直前の確保量が8GiB程です.
このfreeに[B] の6秒が使われているのかな,とか思ったり思わなかったりです.
おわりに
memory poolと言うからにはNVMLでメモリ使用量を見ると,増えていく一方でプログラムの最後に一気に開放するのかなと思っていましたが,実際はfreeによって途中で減っていく様子が見られました.
どういう実装になっているのでしょうね.