CUDAの__device__関数のポインタを用いてif分岐を削除することに速度的優位性はあるか?
消えたCUDA関連の旧ブログ記事を復元するひとり Advent Calendar 2024の記事です.
__device__関数のポインタ
まぁ,ソフトウェア的にifをなくしたところでハードウェアは変わらないので,優位性はないというのが答えです.
CUDAの__device__関数は基本的にはinline展開されるのですが,計算が複雑な再帰関数や関数ポインタを扱う場合はinline展開されず関数が作られcallされます.
このためif分岐を関数ポインタの配列を使って消したりもできそうなのですが,果たしてそれって速いの?というのが今回の記事です.
実験
コードはこんな感じです.
同一warp内で分岐が発生するような__global__関数です.
#include <iostream>
#include <memory>
template <int N>
__device__ float load_array(float *array){
float sum = 0.0f;
#pragma unroll
for(int i = 0; i < 1; i++){
sum += array[i] * N;
}
return sum;
}
template <int N>
__global__ void kernel(float* const array){
const auto tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid >= N - 4) return ;
float (*funcs[])(float*) = {
&load_array<1>,
&load_array<2>,
&load_array<3>,
&load_array<4>
};
array[tid] = (*(funcs[tid%4]))(array+tid);
}
template <int N>
__global__ void kernel_if(float* const array){
const auto tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid >= N - 4) return ;
const auto mod4 = tid % 4;
if(mod4 == 0){
array[tid] = load_array<1>(array + tid);
} else if(mod4 == 1){
array[tid] = load_array<2>(array + tid);
} else if(mod4 == 2){
array[tid] = load_array<3>(array + tid);
} else if(mod4 == 3){
array[tid] = load_array<4>(array + tid);
}
}
int main(){
constexpr std::size_t N = 1 << 30;
constexpr std::size_t T = 1 << 8;
constexpr std::size_t C = 1 << 1;
float *dev_a, *hos_a;
cudaMalloc((void**)&dev_a, sizeof(float)*N);
cudaMallocHost((void**)&hos_a, sizeof(float)*N);
for(auto i = decltype(C)(0); i < C; i++){
kernel<N><<<(N+T-1)/T, T>>>(dev_a);
kernel_if<N><<<(N+T-1)/T, T>>>(dev_a);
}
cudaFree(dev_a);
cudaFreeHost(hos_a);
}
結果がこちら.
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- ------------ ------------ ---------- ---------- ----------- ----------------------------------------
67.7 57,973,434 2 28,986,717.0 28,986,717.0 28,984,124 28,989,310 3,667.1 void kernel<(int)1073741824>(float *)
32.3 27,618,040 2 13,809,020.0 13,809,020.0 13,799,739 13,818,301 13,125.3 void kernel_if<(int)1073741824>(float *)
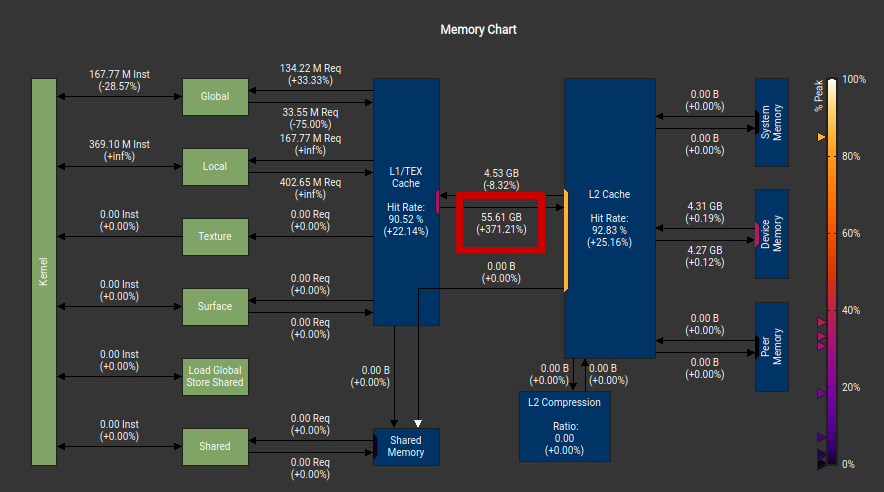
kernel_ifがif分岐,kernelが関数ポインタ配列による疑似分岐の実行時間ですが,if分岐のほうが速いですね.--ptxas-options=-vで見る限り,使用レジスタ数も多いですし,関数ポインタの方ではstackも使用されます(関数呼び出しのため). stack,つまりlocal memoryの使用によるメモリアクセスの増加はNsight Computeのmemory chartで確認できます.
Warp divergenceはどう起きるのか?
例えば上のコードのように4パターンに分岐する場合,device関数の関数ポインタを用いた分岐でも4つにwarpがdivergeするのでしょうか? 逆に言えば,例えば32個にdivergeしてしまうことはないのでしょうか?
というわけで,こんなコードで確認してみます. このコードでは,divergeして入ったdevice関数内でclock64()を呼び,その値をprintします. つまり,printされる値が何通りになるかが,divergeの数になります.
#include <iostream>
#include <cstdint>
template <int N>
__device__ void func(const std::uint64_t start_clock) {
const std::uint64_t clock_diff = clock64() - start_clock;
printf("N=%2d lane_id=%2d clock=%ld\n", N, threadIdx.x, clock_diff);
}
__global__ void kernel(){
const auto tid = threadIdx.x;
const auto start_clock = clock64();
void (*funcs[])(std::uint64_t) = {
&func<1>,
&func<2>,
&func<3>,
&func<4>
};
(*(funcs[tid%4]))(start_clock);
}
__global__ void kernel_if(){
const auto tid = threadIdx.x;
const auto start_clock = clock64();
const auto mod4 = tid % 4;
if(mod4 == 0){
func<0>(start_clock);
} else if(mod4 == 1){
func<1>(start_clock);
} else if(mod4 == 2){
func<2>(start_clock);
} else if(mod4 == 3){
func<3>(start_clock);
}
}
int main(){
cudaDeviceSynchronize();
std::printf("kernel\n");
kernel<<<1, 32>>>();
cudaDeviceSynchronize();
std::printf("kernel_if\n");
kernel_if<<<1, 32>>>();
cudaDeviceSynchronize();
}device関数ポインタの方の出力はこんな感じ.
kernel N= 1 lane_id= 0 clock=845 N= 1 lane_id= 4 clock=845 N= 1 lane_id= 8 clock=845 N= 1 lane_id=12 clock=845 N= 1 lane_id=16 clock=845 N= 1 lane_id=20 clock=845 N= 1 lane_id=24 clock=845 N= 1 lane_id=28 clock=845 N= 2 lane_id= 1 clock=78256 N= 2 lane_id= 5 clock=78256 N= 2 lane_id= 9 clock=78256 N= 2 lane_id=13 clock=78256 N= 2 lane_id=17 clock=78256 N= 2 lane_id=21 clock=78256 N= 2 lane_id=25 clock=78256 N= 2 lane_id=29 clock=78256 N= 3 lane_id= 2 clock=144797 N= 3 lane_id= 6 clock=144797 N= 3 lane_id=10 clock=144797 N= 3 lane_id=14 clock=144797 N= 3 lane_id=18 clock=144797 N= 3 lane_id=22 clock=144797 N= 3 lane_id=26 clock=144797 N= 3 lane_id=30 clock=144797 N= 4 lane_id= 3 clock=210578 N= 4 lane_id= 7 clock=210578 N= 4 lane_id=11 clock=210578 N= 4 lane_id=15 clock=210578 N= 4 lane_id=19 clock=210578 N= 4 lane_id=23 clock=210578 N= 4 lane_id=27 clock=210578 N= 4 lane_id=31 clock=210578
divergenceは4通りで,同じdevice関数を呼ぶ場合はちゃんとまとめて実行されているみたいです. ではこれはコンパイル時に埋め込まれた挙動なのでしょうか?それともランタイムでのスケジューリングなのでしょうか?
PTXを見てみると以下のようになっています.
.visible .entry _Z6kernelv()
{
.local .align 16 .b8 __local_depot4[32];
.reg .b64 %SP;
.reg .b64 %SPL;
.reg .b32 %r<3>;
.reg .b64 %rd<12>;
mov.u64 %SPL, __local_depot4;
add.u64 %rd3, %SPL, 0;
mov.u32 %r1, %tid.x;
//
mov.u64 %rd1, %clock64;
// 関数ポインタを配列に格納
mov.u64 %rd4, _Z4funcILi2EEvm;
mov.u64 %rd5, _Z4funcILi1EEvm;
st.local.v2.u64 [%rd3], { %rd5, %rd4};
mov.u64 %rd6, _Z4funcILi4EEvm;
mov.u64 %rd7, _Z4funcILi3EEvm;
st.local.v2.u64 [%rd3+16], { %rd7, %rd6};
// callする関数を配列から選択
shl.b32 %r2, %r1, 3;
cvt.u64.u32 %rd8, %r2;
and.b64 %rd9, %rd8, 24;
add.s64 %rd10, %rd3, %rd9;
ld.local.u64 %rd11, [%rd10];
// 関数call
{ //
.reg .b32 temp_param_reg;
.param .b64 param0;
st.param.b64 [param0+0], %rd1;
prototype_4 : .callprototype ()_ (.param .b64 _);
call
%rd11,
(
param0
)
, prototype_4;
} //
ret;
}
陽的にcallをまとめているような箇所はないので,ランタイムでのスケジューリングによるものと推測できます.