Nsight Computeでrooflineの図を描く
何の話か
一言で言えば,Nsight Computeでroofline図[1]を描く方法について書いています.
プログラムの最適化を行う上でプロファイリングはとても重要なものです.
プロブラムは計算機上で動作し,その計算機には主要な部品としてプロセッサとメモリがあります.
プロセッサはムーアの法則(もう死んだとも言われていますが)によってトランジスタ数が増加し,発展を遂げてきました.
一方でメモリはこのプロセッサの発展速度と比較して発展が遅いとも言われています.
何が言いたいかと言うと,プロセッサもメモリも有限の性能しかなく,日々変化するこれらの性能比を知らずにプログラムの最適化などできるわけがないということです.
このため,プログラムのプロファイリングにおいて知りたいことの一つとして,実行するプロセッサやメモリが決まっている時,そのプログラムがプロセッサの性能とメモリの性能のどちらに律速されているのか,はたまた同期等のそれ以外の処理で律速されているのかという情報があります.
この記事はこの情報を得るための1指標であるrooflineと呼ばれるものをCUDAのプロファイルでどう取得すればいいかについて書きます.
Nsight Computeでroofline図を描く
とても簡単で,CUDA 11からNsight Computeにroofline図を描く機能が追加されています.[2]
もしコマンドライン上でプロファイル結果をファイルに書き出し,これをNsight Computeで開いて見たい場合は,
ncu -o report --set full -f ./a.outのように--set fullや,--set detailedを付ける必要があるようです.
Nsight Computeで見るとこの様になります.
実行したのはcuBLASのsgemm (m = n = k = \(2^{14}\))です.
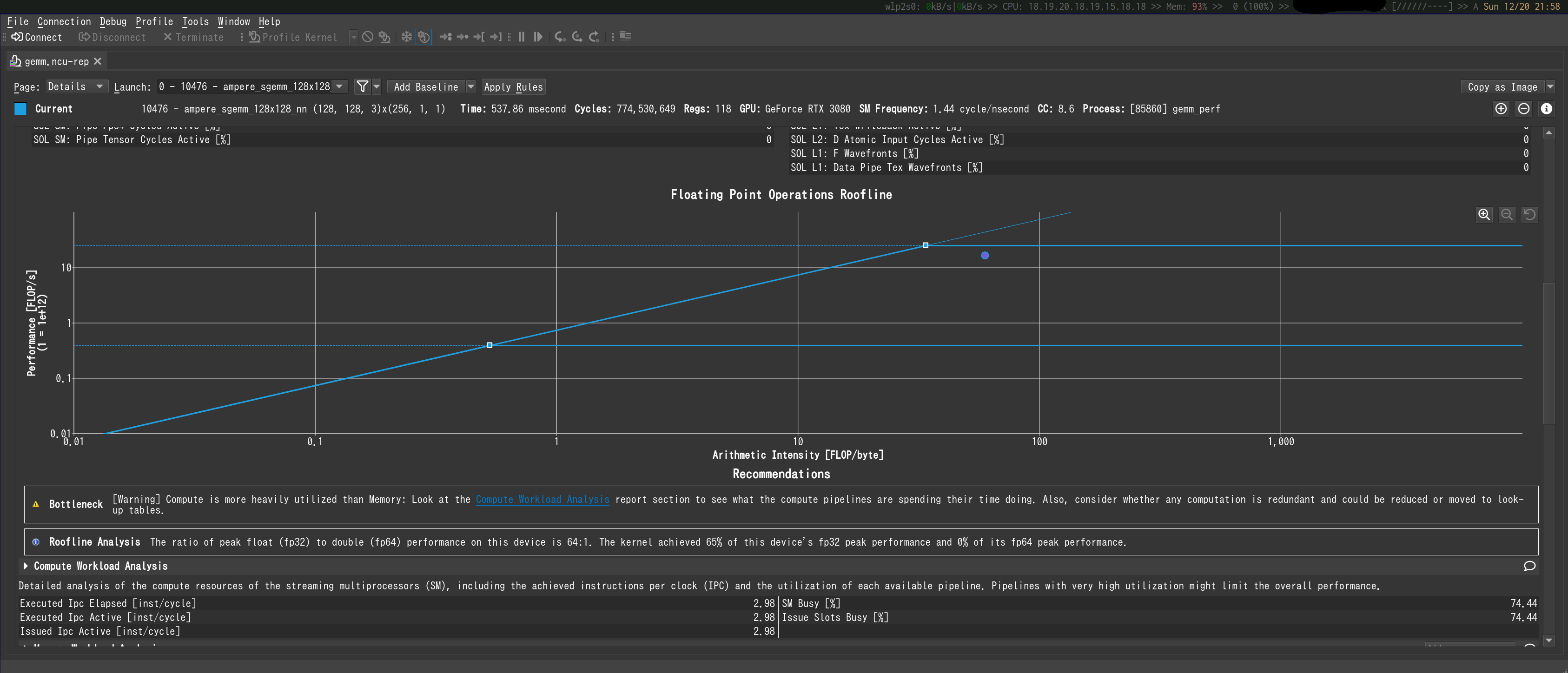
横軸が理論演算量([Flops])と理論データ転送量([Byte])の比Arithmetic Intensity (AI) [Flops/byte]です.
今回だと,cuBLASのsgemmで呼ばれている関数名から察するに,m=n=128, k=\(2^{14}\)な気がするので,
$$\begin{eqnarray}
\text{AI} = \frac{2mnk}{((2mn + mk + kn) \times \text{sizeof(float)})}\sim 64
\end{eqnarray}$$
くらいとなっているのかと思います.
縦軸は実際の計算を行った場合の計算速度で,今回はおおよそ16[TFlop/s]程度だったようです.
図中の青い線がハードウェアの理論性能値です.
左側の斜めっている線がメモリのバンド幅の理論性能値,右側の横軸と平行な線がプロセッサの演算性能値となっています.
プロセッサの方は現在SPとDPの2本が引かれているようです.
で,プロファイリングとして何を見ればいいかと言うと,図中の青い点です.
これがメモリとプロセッサのどちらの理論性能値の線の真下にいるかで,そのプログラムの律速となりうるのがどちらかが分かります.
今回の場合はプロセッサが律速となりうるようです.
また,律速となりうる理論性能値の線との近さによって,どれほど理論性能に近い効率で計算資源を使えているかを知ることができます.
おわりに
Nsight Computeにこの機能が入るまでは自分でAIを計算する必要がありましたが,これを使うと全自動でやってくれるのでとても楽です.
--set fullを付けるとプロファイルがとても遅くはなりますが.