AmpereのTensorコアの話
消えたCUDA関連の旧ブログ記事を復元するひとり Advent Calendar 2024の記事です。
TF32について
Ampereに搭載されているTensorコア Gen 3ではTF32と呼ばれる浮動小数点数を用いることができます.
これは指数部8bit,仮数部10bitの計19bitの浮動小数点数です.
何が32bitだ,とお思いでしょうが,CUDAではfloatとして保持するため,メモリ使用量は32bitです.
要するに,普通に使う分にはメモリの節約には全くなりません.
NVIDIAはこれをcuBLASのGEMM等で使えるようにしており,たまに単精度行列積と謳ってその計算性能を表示しています.
しかし,TF32は仮数部が大きい,すなわち表現範囲可能範囲が広いだけで,仮数部はFP16 (IEEE Binary16)と同じであるため,精度は単精度の足元にも及びません.
FP16ではアンダーフローが起きやすい計算は多少は精度がマシになるかもしれませんが.
この記事はそんなTF32を自分のカーネル関数から使う場合の注意点の話です.
TF32のTensorコアでの使い方
以前からTensorコアはWMMA APIと呼ばれるAPIで利用可能なわけですが,TF32もこれを用いることで利用可能です.
ただし注意点があります.
NVIDIAの資料でこのようなものを見たことがある方も多いかと思います.
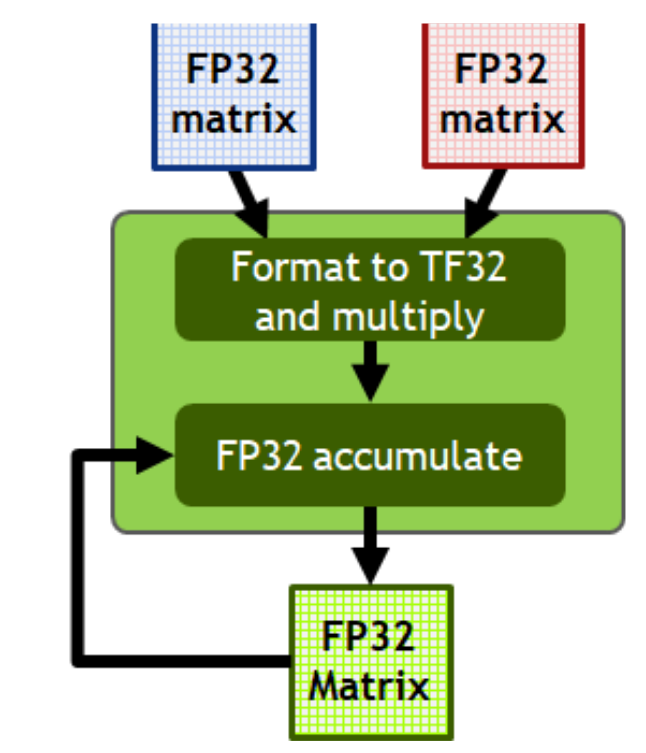
出典 : NVIDIA A100 Tensor コアGPU アーキテクチャ - NVIDIA
これを見ると,Tensorコアはメモリ(本当はfragment/レジスタ)からFP32の行列データを読み,Tensorコアへ送ることで使えるようになる気になります.
上述したとおりTF32はメモリ上ではfloatをして保持され,Tensorコアはこの内MSBから19bitのみを読み込みます.
これは丸めとしてはかなりおそまつなものです(RZ).
少しでも丸めを気にするならば,Tensorコアへ送る前に適切な丸めを自分で行う必要があります.
FP32からFP16への変換(__float2half)はデフォルトでRN(最近接偶数丸め)が使われるため,自分で丸めを行わないと,仮数部的にはFP16よりも変換による精度が劣化する場合があります.
ではどう変換すればいいかと言いますと,PTXのcvt.rna.tf32.f32命令で少しマシな丸めで変換できます.
この命令は零捨一入みたいな丸めを行います.
これはmma.hをincludeしている場合は__float_to_tf32関数がこれをwrapしているため,これを用いて以下のように変換できます.
const float fp32 = 1.0f;
const float tf32 = __float_to_tf32(fp32);PTXでは1命令ですが,少なくともAmpereではSASSレベルで複数のビット演算等に置き換わるので,HWとしては丸め回路を持っていないようです.
おわりに
「自分で変換を行ってね」というのはCUDA Toolkit Documentationにかかれています.