精度補正を加えたTensorコアによる単精度積について
消えたCUDA関連の旧ブログ記事を復元するひとり Advent Calendar 2024の記事です。
追記 : 新たに精度補正に関する研究で論文を出しました。NVIDIA A100上でTensorコアを用いることで、FP32 SIMTコアを用いた場合と同じ精度で、かつFP32の理論ピーク性能以上でSGEMMをエミュレートする研究です。
Hiroyuki Ootomo, Rio Yokota, Recovering single precision accuracy from Tensor Cores while surpassing the FP32 theoretical peak performance, IJHPCA, 2022
CUDA Advent Calendar 2019 2日目の記事です.
自分の修論の内容です.
Tensorコアで単精度行列積を計算したい場合、精度補正がなぜ必要なのか?
Tensorコアへの積計算を行いたい行列はFP16で入力する必要があります.
このためTensorコアがいくら内部でFP32計算を行おうとも計算精度の劣化は免れません.
これほ精度の劣化を修正しようというのが今回の記事の内容です.
実は既存研究もあったりします.
Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, Jeffrey S. Vetter - NVIDIA Tensor Core Programmability, Performance & Precision arXiv:1803.04014
あと,自分の研究でも彼らとはちょっと違いますが使っています.(彼らの手法は無駄があると考えています)
Hiroyuki Ootomo, Rio Yokota - TSQR on TensorCores SC19 Research Poster
どうやって精度を補正するの?
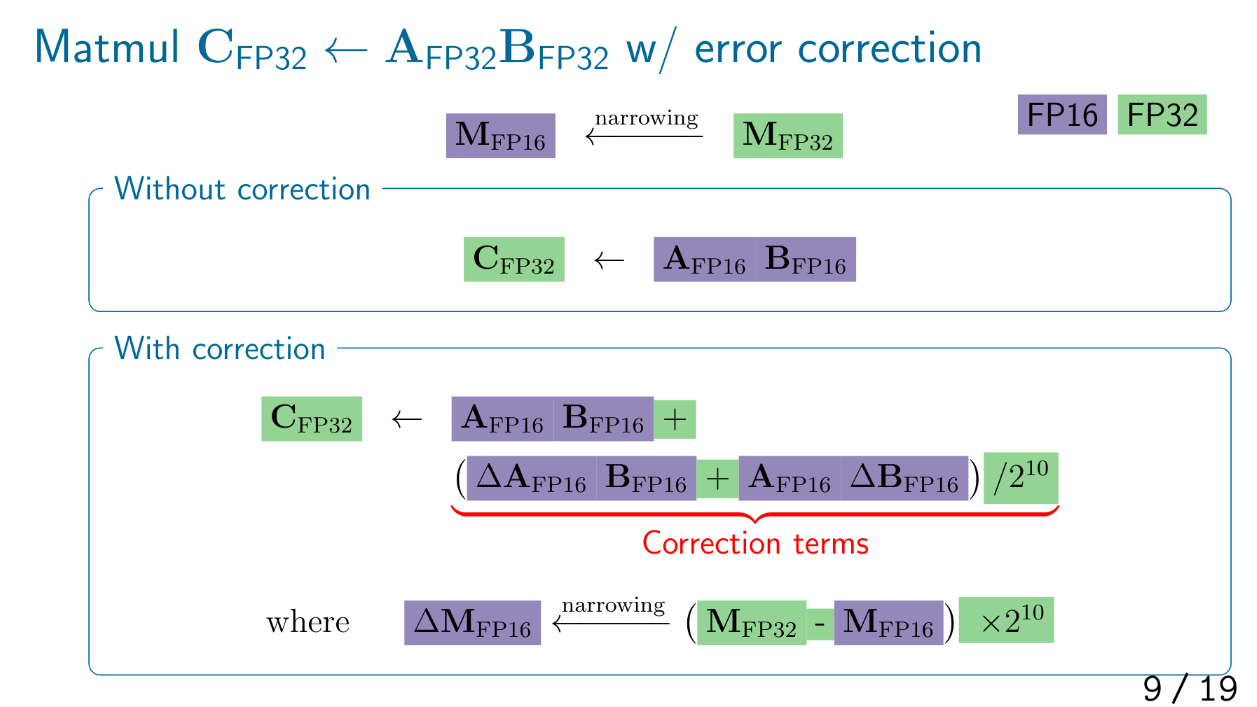
自分の手法ではFP32からFP16に型を落とす際に発生する誤差を別変数でとっておき,これを用いて精度の修正を行っていきます.
この手法では行列積の回数は3倍となり,加えて修正項の計算が入るため計算量は増えます.
しかしそもそもTensorコアの計算速度が速いことなどを考えると(チューニング次第では)いい感じに高速に計算できます.
もっとも,完全にFP32の精度が出るわけではありません.
FP32の仮数部は23bit+ケチ1bitで24bitなのに対しFP16は10bit+1bitで11bitなため,FP16変数2つではFP32の仮数部をすべて表せません.
また,Tensorコア内部の足しこみがFP32なのでFP64行列積の精度修正は難しいです.
指数部長の違いもスケールすれば解決する場合としない場合があります.
おわり
今後のアーキでTensorコアの精度面で何かしらの進歩があると楽しそうですね.