大友 広幸 / Ootomo, HiroyukiHiroyuki Ootomo
- Software / Compute Performance Engineer
- Ph.D. in Computer science from Tokyo Institute of Technology
Research
- 高性能計算High performance computing
- 低精度/混合精度演算Mixed-precision Computing
- 乱択数値線形代数Randomized Numerical Linear Algebra
- 量子回路シミュレーションQuantum Circuit Simulation
- 近似最近傍探索Approximate Nearest Neighbor Search
Skills / Hobbies
- Vim
- C,C++ / CUDA
- Linux (サーバ管理/運用Server management)
活動内容Blog - ピザ窯ちょっと作れるBuilding a pizza oven
- 土器ちょっと焼けるBaking a Jomon pottery
- 廃PC部品でアクセサリを作ったりCreating accessories from used/broken computer parts
- 旅行Travel
Work experience
- 2023.04 -
NVIDIA Compute Developer Technology Engineer- CAGRA (CUDA ANNS Graph-based) [paper]
- etc
- 2021.04 - 2023.03
日本学術振興会特別研究員(DC2/高性能計算) JSPS Research Fellowships for Young Scientists (DC2/High performance computing) - 2022.09 - 2022.11
PEZY Computing (アルバイト)PEZY Computing (part-time job)
発表Presentation- 大友広幸,坂本亮 "PEZY-SC3sプロセッサを用いたFull-state量子回路シミュレーション", 第187回ハイパフォーマンスコンピューティング研究会 2022Hiroyuki Ootomo and Ryo Sakamoto, Full-state Quantum Circuit Simulation on PEZY-SC3s processor, 2022
- 2022.02 - 2022.08
NVIDIA Compute DevTech InternNVIDIA Compute DevTech Intern
発表Presentation - 2021.03 - 2022.02
Fixstars Corporation (アルバイト)Fixstars Corporation (part-time job) - 2020.12 - 2021.01
理化学研究所 計算科学研究センター 粒子系シミュレーションチーム 実習生Riken R-CCS Internship program (Particle Simulator Research Team) - 2020.08 - 2020.10
Future Corporation (アルバイト)Future Corporation (part-time job) - 2019.08 - 2019.09
Preferred Networks インターンシップ(Chip/MN-Coreチーム)Preferred Networks Internship program (Chip/MN-Core team) - 2018.07 - 2020.06
Fixstars Corporation (アルバイト)Fixstars Corporation (part-time job)
発表Presentation - 2018.05 - 2018.06
Fixstars Corporation (インターンシップ)Fixstars Corporation (Internship program)
発表Presentation
Graph:

Research
DGEMM emulation on NVIDIA Int8 Tensor Cores via the Ozaki scheme

尾崎スキームは低精度演算器を用いた高精度行列積アルゴリズムです.
この手法は,入力行列に対し,分割された行列間の積計算中で丸め誤差が発生しないよう分割を行うことで,高い計算精度を実現します.
これは固定小数点演算を介した計算と捉えることができ,Int8 Tensorコアによる演算と相性が良いです.
本研究では,尾崎スキームをInt8 Tensorコアで実装することで,NVIDIA GeForce GPUにおいて倍精度の理論ピーク性能を上回る倍精度行列積を実現しました.
詳しくは 論文 をご覧ください.
The Ozaki scheme is a high-precision matrix multiplication method that uses lower-precision arithmetic.
This scheme splits the input matrices so that the rounding error does not occur in the multiplication of the split matrices.
This can be interpreted as a fixed-point arithmetic method and is suitable for Int8 Tensor Cores.
We show that the scheme using Int8 Tensor Cores outperforms the theoretical peak performance of FP64 CUDA cores in double precision matrix multiplication on NVIDIA GeForce GPUs.
See our paper for more detail.
SGEMM emulation on NVIDIA Tensor Cores with error correction method
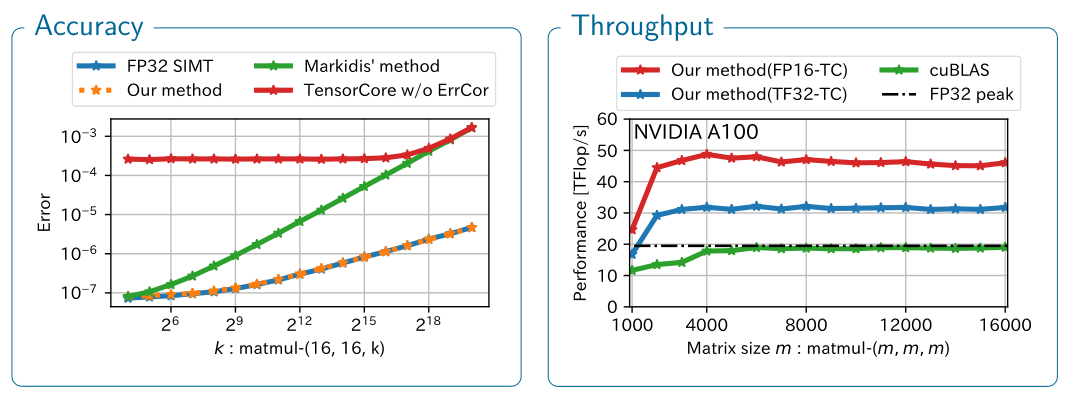
TensorコアはNVIDIA GPU上に搭載された混合精度行列積和演算回路です.
Tensorコアを用いて単精度行列積を計算する場合でも,Tensorコアへの入力行列は半精度である必要があり,これが行列積の精度を劣化させます.
この劣化はTensorコアの特長を活かした精度補正計算を行うことで緩和でき,これに加えTensorコア内部の一部の丸め(RZ)を上手に回避することでFP32と同じ精度で行列積を計算できるようにする研究を行っています.
詳しくは 論文 をご覧ください.
Tensor Cores are specialized hardware for matrix multiplication and addition and are available on the latest NVIDIA GPUs.
Converting input matrices to half precision on TensorCores results loss of accuracy when computing a single-precision matrix multiplication.
We recover the accuracy using an error correction technique and avoiding the rounding inside Tensor Cores (RZ).
See our paper for more detail.
Quantum Circuit Simulation by SGEMM Emulation on Tensor Cores

テンソルネットワーク縮約を用いた量子回路シミュレーションでは,テンソル縮約を行うTTGTアルゴリズムにより,その主たる計算は単精度行列積となる.
NVIDIA Tensorコアは混合精度行列積和演算回路であり,積を計算する行列は低精度(FP16,TF32),内部計算と出力を単精度とする.
Tensorコアを単純に用い単精度行列積を計算する場合,入力行列を低精度へ変換することから,最終的な計算精度が劣化する.
この精度の劣化を補正する単精度行列積エミュレーションを手法では,TF32入力のTensorコアでは完全な単精度エミュレーションが可能であるのに対し,FP16入力のTensorコアを用いた場合ではサポートされる指数部範囲がFP16と同等に限定される.
一方でFP16 Tensorコアを用いることでTF32 Tensorコアを用いた場合より高い計算性能を得られ,ここにトレードオフが存在する.
本研究では,行列積において積を計算する行列の指数部分布を積計算の直前に解析し,これを用いてTensorコアの入力精度を切り替え,可能な範囲でFP16 Tensorコアを使用する手法を提案する.
詳しくは 論文 (ISC High Performance 2023) をご覧ください.
Single-precision complex matrix multiplication is the primary computation of quantum circuit simulation by tensor network contraction.
We improve the throughput of the simulation using SGEMM emulation on Tensor Cores.
There are two kinds of SGEMM emulation method implementation: TF32TCEC and FP16TCEC.
While TF32TCEC uses TF32 Tensor Cores and can be an alternative to SGEMM, the supported exponent range for input matrices is smaller than FP32 in FP16TCEC, which uses FP16 Tensor Cores.
However, TF32TCEC has higher throughput than FP16TCEC.
Therefore, there is a trade-off between the supported exponent range and throughput.
We propose an automatic precision selection to choose which Tensor Core to use.
This method checks the exponent distribution of the input matrices before computing a matrix multiplication.
See our paper (ISC High Performance 2023) for more detail.
Custom 8-bit floating point value format for ANNS/IVFPQ on GPU
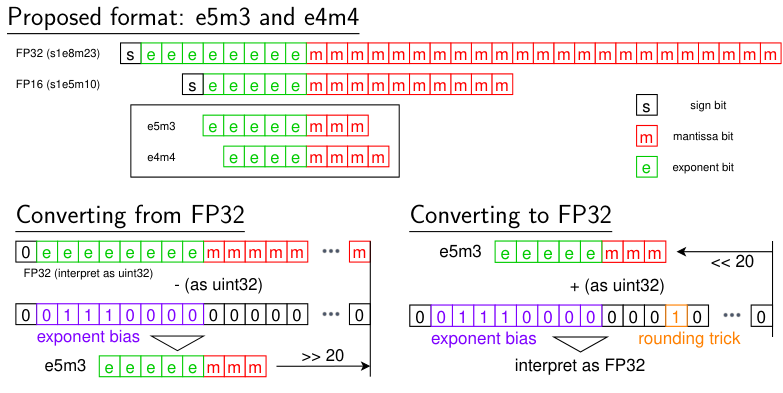
近似最近傍探索(ANNS; Approximate Nearest Neighbor Search)のアルゴリズムの一つであるIVFPQをGPU用に実装する場合,Sharedメモリに対するランダムアクセスによりバンクコンフリクトが発生し,性能が低下する可能性がある.
バンクコンフリクトを緩和する方法として低bit長変数の使用が挙げられ,GPU上で値の保持だけに用いる低変換コストな8-bit浮動小数点数の設計を行います.
IVFPQの性質上値は常に0以上であるため符号部は不必要であるなど,アプリケーションの性質に合わせたものとなっており,IVFPQにおいて多少の性能劣化を許容すれば計算性能を向上させることが確認されています.
詳しくはポスターをご覧ください.
When implementing IVFPQ, one of the algorithms of ANNS (Approximate Nearest Neighbor Search), for GPU, the shared memory bank conflict may occur.
One of the ways to reduce the probability of bank conflict is to use a low-precision variable for the data on shared memory.
We design an 8-bit floating point value format specialized for IVFPQ.
For instance, the format does not have the sign bit since the values are always positive.
Our format increases the throughput of IVFPQ on GPU while a bit of accuracy degradation.
See our poster for more detail.
Publications (Peer-reviewed)
- Hiroyuki Ootomo, Katsuhisa Ozaki and Rio Yokota, "DGEMM on Integer Matrix Multiplication Unit", IJHPCA, 2024 [journal][preprint]
- Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, Yong Wang, "CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs", ICDE 2024, [paper][preprint]
- Hiroyuki Ootomo and Rio Yokota, "Mixed-Precision Random Projection for RandNLA on Tensor Cores," PASC'23, 2023 [preprint][paper][slides]
- Hiroyuki Ootomo, Hidetaka Manabe, Kenji Harada, and Rio Yokota, "Quantum Circuit Simulation by SGEMM Emulation on Tensor Cores and Automatic Precision Selection", ISC high performance, 2023, [paper][preprint][slides]
- Hiroyuki Ootomo, Rio Yokota, "Reducing shared memory footprint to leverage high throughput on Tensor Cores and its flexible API extension library", HPCAsia, 2023 (Best Paper) [link]
- Shaoshuai Zhang, Ruchi Shah, Hiroyuki Ootomo, Rio Yokota, Panruo Wu, "Fast Symmetric Eigenvalue Decomposition via WY Representation on Tensor Core", PPoPP, 2023 [link]
- Hiroyuki Ootomo, Akira Naruse, "Custom 8-bit Floating Point Value Format for Reducing Shared Memory Bank Conflict in Approximate Nearest Neighbor Search", SC22 Research Poster, 2022 [abstract][poster]
- Hiroyuki Ootomo, Rio Yokota, "Recovering single precision accuracy from Tensor Cores while surpassing the FP32 theoretical peak performance", IJHPCA, 2022 [journal][preprint]
- Hiroyuki Ootomo, Rio Yokota, "Randomized SVD on TensorCores", ISC 2020 Research Poster [link]
- Hiroyuki Ootomo, Rio Yokota, "TSQR on Tensor Cores", SC19 Research Poster, 2019 [Best Poster Candidate] [poster][slides]
Publications & Presentations (Non peer-reviewed)
- Hiroyuki Ootomo, "What GPU Engineer Think About When Designing Graph-based ANNS (GPU-oriented High-Performance Graph-based Approximate Nearest Neighbor Search)," The 1st Workshop on Vector Databases (VecDB), 2025 [link]
- Hiroyuki Ootomo, "DGEMM on Integer Tensor Cores," NHR PerfLab Seminar, 2023 [slides]
- 大友広幸,真鍋秀隆,原田健自,横田理央 "Tensorコアによる単精度行列積エミュレーションの自動精度選択を用いた量子回路シミュレーション", 第188回 HPC研究会, 2023 [link]
- 大友広幸 "NVIDIA Tensorコアを用いたテンソルネットワーク型量子回路シミュレーション", 第18回 High Performance Computing Physics (HPC-Phys) 勉強会, 2023 [slides (Ja)]
- 大友広幸,坂本亮 "PEZY-SC3sプロセッサを用いたFull-state量子回路シミュレーション", 第187回ハイパフォーマンスコンピューティング研究会, 2022
- 真鍋秀隆, 大友広幸 "Tensorコアを用いた量子回路シミュレーションの高速化" 第7回量子ソフトウェア研究発表会, 2022
- 大友広幸,横田理央 "NVIDIA Tensorコアを用いた単精度行列積エミュレーション" RIMS共同研究 (公開型) 数値解析が拓く次世代情報社会~エッジから富岳まで~, 2022
- 大友広幸,横田理央 "Tensorコアを用いた単精度行列積エミュレーションのアプリケーションでの評価" 第185回ハイパフォーマンスコンピューティング研究会 (SWoPP 2022)
- Hiroyuki Ootomo, Rio Yokota "Recovering single precision accuracy from Tensor Cores while surpassing the FP32 theoretical peak performance", ECP multiprecision team meeting [slides]
- 大友広幸,横田理央 "Tensorコアを用いた精度補正単精度行列積" 第180回ハイパフォーマンスコンピューティング研究会 (SWoPP 2021)
- Hiroyuki Ootomo, Rio Yokota "TSQR on TensorCores with error correction", SIAM CSE'21[slides]
- 大友広幸,横田理央 "TensorコアのAPIの構造解析を用いた拡張ライブラリの開発" 第173回ハイパフォーマンスコンピューティング研究会 2020 [link]
- 吉藤尚生,大友広幸 "粒子法FLOSSに対する妥当性確認試験" 第33回数値流体力学シンポジウム 2019 [blog]
- 大友広幸,横田理央 "Tensorコアを用いたTSQR" 日本応用数理学会 2019年度 年会 2019
- 大友広幸,横田理央 "Tensorコアを用いたTSQRのGPU実装" 第170回ハイパフォーマンスコンピューティング研究会 2019
- 大友広幸,横田理央 "Tensorコアを用いたBatced QR分解" 情報処理学会第81回全国大会 2019 [学生奨励賞]
- 大友広幸,大沢和樹,横田理央 "フィッシャー情報行列のクロネッカー因子分解を用いた深層学習" 情報処理学会第80回全国大会 2018
- 大友広幸,大沢和樹,横田理央 "フィッシャー情報行列のクロネッカー因子分解を用いた深層ニューラルネットワークの分散学習"第163回ハイパフォーマンスコンピューティング研究会 2018
- Hiroyuki Ootomo, "What GPU Engineer Think About When Designing Graph-based ANNS (GPU-oriented High-Performance Graph-based Approximate Nearest Neighbor Search)," The 1st Workshop on Vector Databases (VecDB), 2025 [link]
- Hiroyuki Ootomo, "DGEMM on Integer Tensor Cores," NHR PerfLab Seminar, 2023 [slides]
- Hiroyuki Ootomo, Hidetaka Manabe, Kenji Harada, Rio Yokota, "Quantum Circuit Simulation by SGEMM Emulation on Tensor Cores and Automatic Precision Selection," IPSJ HPC Workshop #188, 2023 [link]
- Hiroyuki Ootomo, "Quantum Circuit Simulation by Tensor Network Contraction on NVIDIA Tensor Cores," High Performance Computing Physics (HPC-Phys) Workshop #18, 2023 [slides]
- Hiroyuki Ootomo, Ryo Sakamoto,"State-vector Quantum Circuit Simulation on PEZY-SC3s Processor," IPSJ HPC Workshop #189, 2022
- Hidetaka Manabe, Hiroyuki Ootomo, "Throughput Improvement of Quantum Circuit Simulation using NVIDIA Tensor Cores," IPSJ Quantum Software Workshop #7, 2022
- Hiroyuki Ootomo, "SGEMM Emulation on Tensor Cores," RIMS Workshop, 2022
- Hiroyuki Ootomo, Rio Yokota, "Applying SGEMM emulation on Tensor Cores to HPC Applications," IPSJ HPC Workshop #185 (SWoPP), 2022
- Hiroyuki Ootomo, Rio Yokota, "Recovering single precision accuracy from Tensor Cores while surpassing the FP32 theoretical peak performance," ECP multiprecision team meeting [slides]
- Hiroyuki Ootomo, Rio Yokota, "SGEMM Emulation on Tensor Cores," IPSJ HPC workshop #180 (SWoPP), 2021
- Hiroyuki Ootomo, Rio Yokota, "TSQR on TensorCores with error correction", SIAM CSE'21[slides]
- Hiroyuki Ootomo, Rio Yokota, "Tensor Core Device API Extension Library," IPSJ HPC workshop #176, 2020 [link]
- Naoki Yoshifuji, Hiroyuki Ootomo, "Validation for Particle Method FLOSS," JSFM CRFD33, 2019 [blog]
- Hiroyuki Ootomo, Rio Yokota, "TSQR on Tensor Cores," JSIAM annual meeting, 2019
- Hiroyuki Ootomo, Rio Yokota, "TSQR on Tensor Cores," IPSJ HPC Workshop #170, 2019
- Hiroyuki Ootomo, Rio Yokota, "Batch QR on Tensor Cores," IPSJ Annual meeting, [Student Award]
- Hiroyuki Ootomo, Kazuki Owasa, Rio Yokota, "Deep Neural Network Training using Kronecker Factorizrion of Fisher Information Matrix," IPSJ Annual meeting #80, 2018
- Hiroyuki Ootomo, Kazuki Owasa, Rio Yokota, "Distributed Deep Neural Network Training using Kronecker Factorizrion of Fisher Information Matrix," IPSJ HPC Workshop #163, 2018
Other publications / presentations
- 2022.06 「"Near-Optimal" Designes (前半)」 高性能プロセッサー設計の専門書 輪読会 #04
- 2019.06 「DualSPHysicsで静水圧問題」 第76回オープンCAE勉強会@関東(流体など)【大崎】 - [発表後記]
- 2019.04 「vim入門」 第0回 #061_vimvimvim - [slides]
- 2022.06 "Principles of High-Performance Processor Design Reading Circle" Principles of High-Performance Processor Design Reading Circle #4
- 2019.06 "Hydrostatic pressure problem on DualSPHysics" 76th Open CAE study group, Kanto area - [Fixsraes tech blog]
- 2019.04 "Introduction to vim" #061_vimvimvim - [slides]
Awards
- 2024年度 手島精一記念研究賞(博士論文賞)
- Best Paper Award of HPC Asia 2023
- 2022年度 山下記念研究賞 2022 - Webページ
- 第3回 HAKKO熱の実験コンテスト 銀賞 「計算パーツの熱に関する実験」 2020 - 詳細
- 情報処理学会全国大会 学生奨励賞 2019 - Webページ
- Seiichi Teshima Research Award (Doctoral Thesis), FY2024
- Best Paper Award of HPC Asia 2023
- IPSJ Yamashita SIG Research Award 2022 - Web page (Japanese)
- 2nd prize of heat experiment contest 2020 by HAKKO Corporation - Detail (Japanese)
- Student Encouragement Award of IPSJ National Convention 2019 - Webページ
Projects
High performance ATSUKAN Computing

I built a GPU cluster to make hot sake (atsukan;熱燗).
Each node has two NVIDIA Tesla K20 GPUs and liquid cooling modules.
Gathered heat through cooling water is used to heat up sake.
8枚のNVIDIA K20xの排熱を利用して熱燗を作るための計算機クラスタを作成しました.
[Blog (Japanese)}
What can a thief steal?

I put a private key printed on a paper at the university.
How much time and interest can I steal from people?
[detail (Japanese)}
秘密鍵を印刷した紙を大学内に置きました.
[詳細]
WMMA API extension
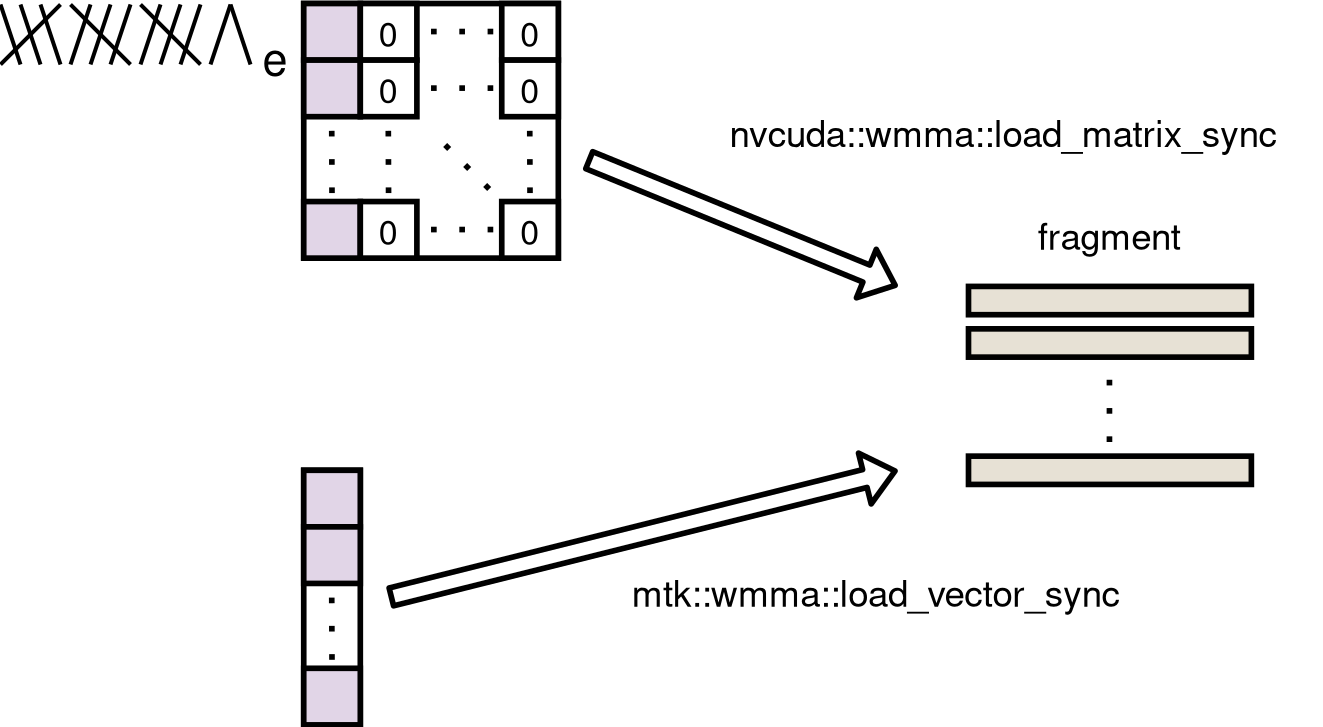
An extension library for WMMA API (TensorCore API).
wmma-extension - GitHub
wmma-extension - GitHub
Tensorコアを効率的に用いるための拡張ライブラリ.
wmma-extension - GitHub
wmma-extension - GitHub
Baking Jomon pottery縄文土器

I get clay from the ground and bake Jomon pottery(縄文土器).
Blog (Japanese)
自宅の庭を掘って粘土を取り出し縄文式土器を焼いています.
Blog (Japanese)
Pizza ovenピザ窯づくり

built a pizza oven in my house.
試行錯誤しながら家にピザ窯を作っています.
Computer parts accessories廃PC部品アクセサリ

accessories from old/broken computer parts.
廃PC部品を再利用してペンダントなどのアクセサリを作成しています.
Web page (Japanese)
Web page (Japanese)
NN-Image

A web service which generates undirected fully-connected graph.
nn-image
全結合ニューラルネットワークの画像をさくっと作れるWebサイト.
nn-image
Iceberg wallpaper generator


TA/RA
- 2017.04 - 2023.03
横田理央研究室 RA - 2019.04 - 2022.03
情報理工学院 数理・計算科学系 森研究室 RA - 2021.01 - 2021.03
産業技術総合研究所 テクニカルスタッフ
- 2017.04 - 2023.03
Research assistant at Yokota Lab, School of computing, TokyoTech - 2019.04 - 2022.03
Research assistant at Mori Lab, School of computing, TokyoTech - 2021.01 - 2021.03
Technical staff at National Institute of Advanced Industrial Science and Technology (AIST)
Educational background
- 2020.04 - 2023.09
東京工業大学情報理工学院情報工学系(博士課程) 横田理央研究室 [博士論文][公聴会スライド]School of computing, TokyoTech (Ph.D). Supervisor: Dr. Rio Yokota [dissertation][defense slides (Japanese)] - 2018.04 - 2020.03
東京工業大学情報理工学院情報工学系(修士課程) 横田理央研究室School of computing, TokyoTech (Master of Engineering). Supervisor: Dr. Rio Yokota - 2014.04 - 2018.03
東京工業大学工学部情報工学科(学部)School of computing, TokyoTech (Bachelor of Engineering) - 2010.04 - 2013.03
埼玉県立川越高等学校Kawagoe high school, Saitama prefecture